
Felicific calculus and making yourself legible to machines


Can I use AI to quantify my own job market value in a way that is more useful than LinkedIn Premium?
Way back in 1789, Jeremy Bentham (the Panopticon guy) introduced the concept of felicific calculus, an algorithm that could be used "for calculating the degree or amount of pleasure that a specific action is likely to induce." Using seven different variables, he believed you could mathematically determine the morality of any action. The idea caused a stir with its promise of a scientific way to quantify morality. Of course, it is practically difficult to measure the intensity and duration of pleasure, and even more challenging to use the outcome as a way to predict the future. But the illusion of precision is tempting.
So why am I taking this trip in the Waaaaayback Machine? We're in another age where a dominant motivation is to make ourselves legible to math, machines, and software. We track our sleep, blood pressure, water intake, steps taken, how often we stand up, respiratory rate, blood oxygen levels, our physical locations, categories of monthly spending, energy usage, environmental noise levels, the number of calories we consume, and more. We are capturing more and more data every day to quantify and understand the world around us. It's at least part of the promise of LinkedIn Premium where insights and data can help optimize your profile and assess your fit for a posted job. That impulse was also the inspiration for my newest project: a system for analyzing and assessing job postings that interest me to help gauge whether or not they are worth the effort of applying to.

Temporarily and unimaginatively named JobSearchHub, it is a personal tool that helps me triage hundreds of job listings. It runs entirely on my computer so there is no cloud, no AI API costs. Here's how it works in four stages:
1. Pulls listings in
Every day, the app reaches out to job-board APIs (Greenhouse, Lever, Ashby, We Work Remotely, Remote OK, Himalayas) and ingests the posts. The listings get aggregated in one place for me to work from instead of having to sift through multiple sites, searches, and email digests. Each source is a small plugin so I can easily extend the list with another file and expand my search radius. For sites that block automated access (e.g. LinkedIn, Indeed, BuiltIn), I have a browser bookmarklet that grabs the page of a job that looks promising and saves it to the local database with one click.
Everything lands in a single SQLite file. Currently: ~625 listings from ~280 companies.
2. Classifies what each listing is
A set of pattern-matching rules reads each job description and tags it: what's the role (Product Designer? Design Manager? something adjacent?), what's the seniority (Senior, Staff, Principal?), is it an individual-contributor or manager role, where is it located, is it remote-friendly. It's all just regex and keyword lookups (no AI), which is fast, free, and inspectable. This approach feels like something that will be easier to develop trust in over time.
3. Filter out the obvious mismatches
Before scoring anything, hard rules eliminate the listings that are non-starters:
- Not in Seattle and not remote → out
- Salary band below my floor → out
- Crypto, gambling, or gaming companies → out
- Specific blocked companies (Axon, Palantir, Anduril) → out
- Wrong kind of role entirely → out
Filtered listings aren't deleted. They go into a "Filtered" drawer with a visible reason, so I can audit why something got excluded and override it if needed.
4. Score what's left
Each surviving listing gets a 0–100 Fit score built from nine weighted categories:
| Category | What it measures |
|---|---|
| Skills | How many of my resume skills appear in the job description |
| Experience level | Does the seniority match where I am in my career |
| Recent industry | Does the company's industry match my last ~10 years of work |
| Scope | Does the responsibility level match |
| Domain alignment | Is it in a domain I care about (climate, healthcare, gov, education) |
| Compensation | Does the posted band match my target |
| Company signal | Is the company stage and ethics profile clean |
| Tools | Does my software experience match |
| Location | Are the working hours Pacific-friendly |
The category scores roll up into one weighted total. Every listing also shows the breakdown so the math is visible on the surface and effectively counters any impulsive and emotional reactions to jobs that interest me. It's not a black box, every number has a "why" that I can evaluate and feels distinct from the opaque and dubious "You're a Top Applicant" fanfare I regularly see on LinkedIn. In theory, the jobs that best align with my qualifications, requirements, and values become legible to me.
5. Three extra signals, separated on purpose
Three other axes are tracked independently that help to make the realities of the job market more tangible, but that are never folded into the Fit score:
- Competitiveness tier (1–5): how much applicant volume a brand attracts. A high-Fit role at Google is still high-Fit; the tier tells me to apply with a referral or not at all. Surfaced as a badge, it never silently downranks the listing.
- Serendipity score: for adjacent roles (Design Operations, PM at a design-led company, non-design roles in priority domains). This section is capped at 3 picks per cycle in a separate widget. The point is to expand my gaze without diluting the main queue.
- Reasons to pause: this is the critical voice that helps articulate sober reasons why choosing not to move forward isa worth considering.
What I see
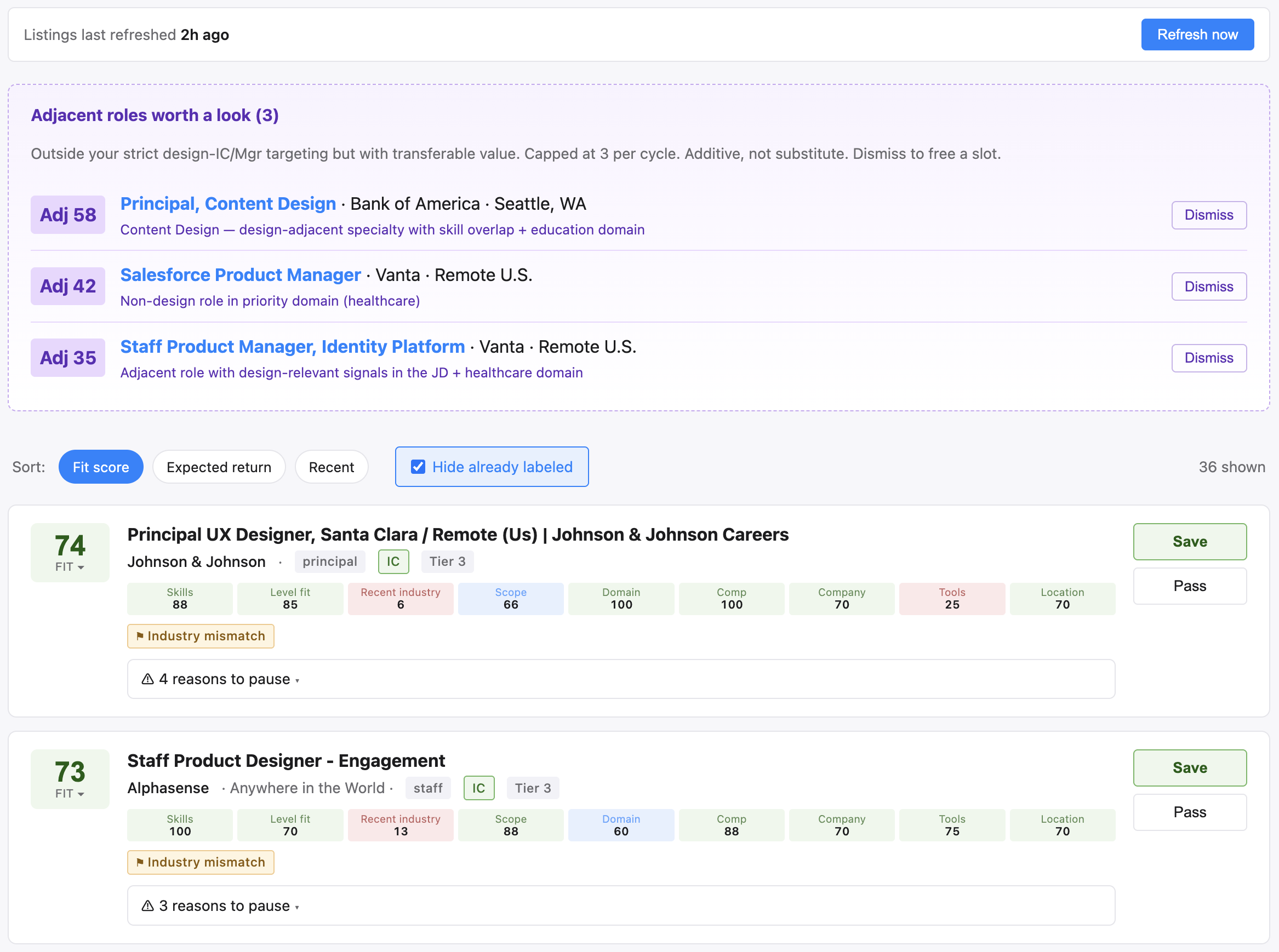
- Triage page: the focused queue with the listings that passed all hard filters, sorted by Fit, with the adjacency widget at the top. (The UI is a dog's breakfast, but I can update that if the tool proves its usefulness.)
- Listings page: the broader inventory, including filtered-out items (which show up without a Fit score so I know they exist but understand they're excluded.)
- Detail page per listing: full score breakdown, advisor warnings (e.g. "far above your level," "competition is heavy here"), research links, and a coverage section showing which terms from the job description matched my resume.
The principle behind all of this
The tool surfaces signal but I make the decisions. Every score is explainable, every filter has a visible reason, and nothing is silently hidden. The goal is fewer, better applications so I can focus my energy on the best fits with the best odds. If we go back to my first post and assess whether this tool is more Ripley or more Edgar, this feels distinctly more Ripley to me. It's is certainly something that would not have been possible for me to create on my own, like Eye•Full before it, and feels like an extension of my capabilities rather than a surrogate.

There are still so many questions. Is the system parsing and analyzing job listings accurately? Many early examples tripped on important data like location because multiple locations were listed in the post or multiple posts were made for the same position with different locations listed. Are the weights for the Fit score effective or am I steering myself towards mirages because the math is faulty? Can we faithfully predict what might happen with the human recruiters and hiring managers on the other side who are inundated with applications from people just like me? It's still too early to say. But the question and the experiment are both meaningful to me. I am starting with a platform that I can experiment with, refine, and personalize in ways that LinkedIn never will. And if it keeps me engaged in my job search, regardless of the outcome, that is its own kind of benefit.
Of course, this is just one component of a larger and more complex system. Comparing job descriptions to a canonical version of my resume does not solve the problem on its own. The market is still hugely competitive, the economics have shifted, and the role of AI has changed the calculus around staffing. Companies are leaning on existing employees to be more productive with AI tools. Block recently laid off nearly half of its staff because of AI. Things are...messy. So the last component of of my strategy is a renewed focus on my networking efforts. My calculus has to also make room for all of you. The recommendation from someone who knows me and my work, or a lead on a position that isn't public yet, doesn't fit easily into this algorithm. If you want to be legible to the job market machine these days, it's the conversations and relationships with real people, the ones who respect your work and enjoy your company, that are the most important inputs of all. So keep an eye out for me on LinkedIn. I might be messaging you soon.
As someone who is trying to establish some agency in a hiring environment that feels wildly automated, this song has been an unofficial anthem.



